In modern cloud systems, it’s not enough to retry — you need to retry smarter. In this post, you’ll learn how to retry smarter with AWS SQS by using exponential backoff, DLQs, and visibility timeouts to avoid failures.
Why Retrying Fails When Done Wrong
Retrying sounds simple — if something fails, just try again. But in distributed systems, naive retries often do more harm than good.
🚨 Message Storms and System Overload
Imagine a scenario where a queue consumer retries a failed request every second without any delay. Now scale that to hundreds or thousands of messages failing simultaneously — what you get is a message storm. This flood of retries:
- Overwhelms the target service (e.g., your webhook endpoint or third-party API).
- Consumes unnecessary resources (CPU, bandwidth).
- Amplifies the original issue instead of helping to resolve it.
In essence, blind retries can turn a small outage into a full-blown incident.
🧟 The “Retry-Until-Death” Anti-pattern
This happens when a system retries a failed message endlessly without proper limits or backoff. It leads to:
- Wasted compute cycles on hopeless retries (e.g., retrying a 401 Unauthorized).
- Queue bloat, as failed messages loop endlessly.
- No feedback loop, meaning developers don’t even know something is broken unless monitoring is in place.
This anti-pattern is especially common in DIY queue consumers that lack built-in retry logic or use a simplistic loop like:
Without intelligent controls, retries can become a self-sustaining infinite loop of failure.
SQS Retry Logic Internals
To design fault-tolerant systems with Amazon SQS, it’s essential to understand how retry behavior is governed internally. SQS doesn’t retry messages in the traditional sense — instead, it relies on two key features: Visibility Timeout and Redrive Policy.
⏳ Visibility Timeout
When a message is picked up by a consumer, it becomes invisible to other consumers for a set period — this is the visibility timeout.
- If the message is processed and deleted before the timeout expires — great!
- If the consumer fails to delete it (e.g., due to a crash, exception, or timeout), the message becomes visible again and re-enters the queue, effectively creating a retry.
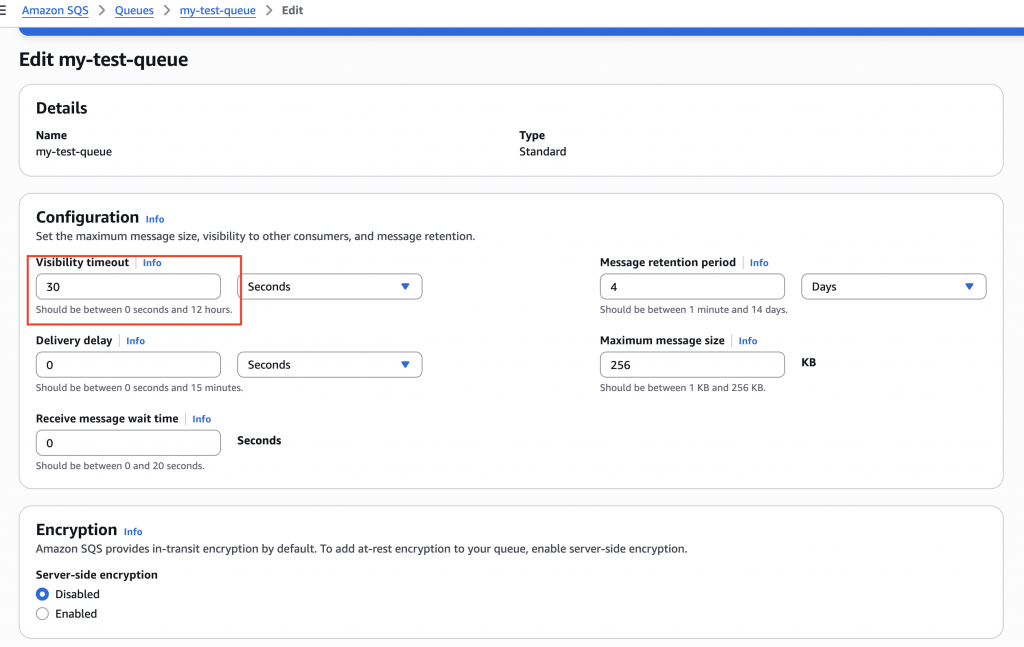
🔁 This is how retries happen in SQS — by re-delivering unacknowledged messages.
Example:
If visibility timeout is set to 30 seconds, and the consumer fails to delete the message within that time, SQS will allow another consumer (or the same one) to pick it up again after 30 seconds.
🔁 Redrive Policy
Retries don’t go on forever. With a Redrive Policy, you can define:
- A Dead Letter Queue (DLQ) — a secondary SQS queue to capture messages that failed too many times.
- A maxReceiveCount — the maximum number of times a message is allowed to be received (retried) before being moved to the DLQ.
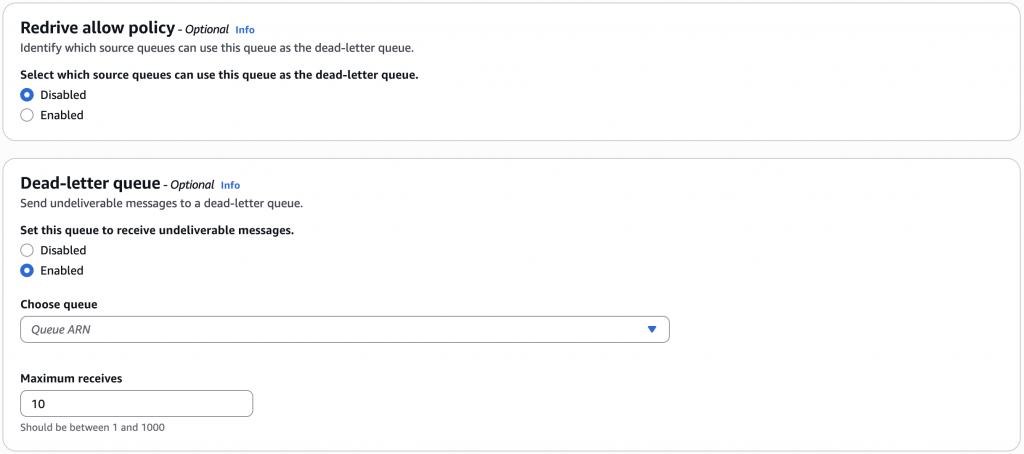
🧠 This is where retry control actually happens in SQS.
Example Configuration:
With this setup, if a message fails 5 times (i.e., is received but never deleted), it is sent to the DLQ for further inspection.
📉 How Many Retries Happen Before DLQ?
The retry count = maxReceiveCount – 1
If you set maxReceiveCount = 5, a message is retried 4 times before it is pushed to the DLQ on the 5th failure.
🔍 Important Notes:
Every retry is spaced by the visibility timeout.If the visibility timeout is too short and the consumer is slow, it may cause false retries.Messages in the DLQ are not retried automatically — you need to monitor and handle them manually.
Exponential Backoff in Practice
When a system is experiencing failures, retrying immediately and repeatedly is a recipe for disaster. The smarter approach? Exponential backoff — a strategy that introduces gradually increasing delays between retry attempts to reduce load and give the system time to recover.
📈 What is Exponential Backoff?
Exponential backoff is a technique where the delay between retries increases exponentially after each failure. A basic formula looks like this:
For example, with a base delay of 1 second:
• 1st retry → 2 seconds
• 2nd retry → 4 seconds
• 3rd retry → 8 seconds
… and so on.
This approach reduces the retry frequency over time, lowering the risk of overloading your service or API during outages.
🌀 Add Jitter to Prevent Thundering Herd
If all clients retry at the same exponential intervals, they might still spike at the same time — known as the thundering herd problem. To avoid this, introduce jitter (randomness) into your delays.
Example with jitter:
This spreads out retries more evenly and helps your system remain stable under pressure.
🛠 Exponential Backoff in AWS SDK
The AWS SDKs implement exponential backoff with jitter by default for most service calls, including SQS. You can customize retry settings if needed, for example in Node.js:
This ensures:
• Controlled retries
• Graceful recovery from transient failures
• Better resilience without code complexity
🎯 When to Use Backoff
Use exponential backoff when:
• The failure is likely temporary (e.g., network timeout, 5xx errors)
• You’re consuming from queues (e.g., SQS, Kafka)
• You’re calling flaky APIs or services that rate-limit
Don’t use it blindly. If you hit client-side bugs or validation errors (4xx), backoff won’t help — and that’s where the next section comes in.
4xx vs 5xx: When to Retry, When to Drop
Not all failures are created equal. To implement smart retry logic, it’s critical to distinguish between client errors (4xx) and server errors (5xx) — because only one of them is worth retrying.
🚫 4xx Errors: Permanent Failures – Don’t Retry
4xx errors indicate that the request itself is invalid, and retrying it without fixing the root cause will never succeed. These are permanent failures and should be logged, alerted, or sent to a DLQ, not retried endlessly.
Common 4xx examples:
• 400 Bad Request: Malformed payload
• 401 Unauthorized: Missing or invalid credentials
• 403 Forbidden: You don’t have permission
• 404 Not Found: Resource doesn’t exist
• 422 Unprocessable Entity: Fails validation
🔍 Retrying these is pointless — in fact, it may create more problems (like rate limiting or blocked IPs).
🔁 5xx Errors: Transient Failures – Retry with Backoff
5xx errors usually mean something is wrong on the server side — a temporary issue that might resolve on its own. These are exactly the kind of failures where retries make sense, especially with exponential backoff and jitter.
Common 5xx examples:
• 500 Internal Server Error
• 502 Bad Gateway
• 503 Service Unavailable
• 504 Gateway Timeout
💡 These are your retry candidates, but with limits — don’t keep retrying forever.
⚡ Real-World Example: Webhook Handling
Let’s say your system receives webhook events (e.g., payment notifications from Stripe or messages from Beeceptor). If your endpoint returns:
• 200 OK → message is successfully handled
• 401 Unauthorized → probably a bad token → don’t retry
• 500 Internal Server Error → maybe a temporary database glitch → retry with backoff
In this case:
• Retry only for retryable failures
• Drop or send to DLQ for permanent ones
• Log all failures with enough context for investigation
🧠 Pro Tip: Categorize and Tag Errors
When building a retry mechanism, tag your failures:
• permanent: log and skip or DLQ
• transient: retry with backoff
• unknown: maybe retry once, then DLQ if it persists
This classification helps make retry decisions deterministic and traceable.
Transient vs Permanent Failures
When dealing with message retries in systems like SQS, it’s important to go beyond HTTP status codes and start thinking in terms of failure types: transient and permanent. Knowing the difference can help you avoid retrying the wrong errors—or worse, dropping the right ones.
🔄 Transient Failures: Try Again (with Care)
Transient failures are temporary issues that usually resolve on their own. These are safe to retry — but only with controlled logic, such as exponential backoff and retry caps.
Examples:
• Network timeouts
• Database connection pool exhaustion
• Temporary API throttling (429 Too Many Requests)
• Intermittent 5xx errors from third-party services
💡 With transient failures:
• Always log and monitor retry counts
• Use alerts if retry frequency spikes
• Move to DLQ after max retries, don’t loop infinitely
🚫 Permanent Failures: Fail Fast and Move On
Permanent failures are caused by problems with the data, logic, or permissions, not temporary issues. Retrying these won’t help and just wastes resources.
Examples:
• Invalid payloads (400, 422)
• Missing resources (404)
• Authentication or access issues (401, 403)
• Domain-specific logic failures (e.g., “user is blocked”, “exam already submitted”)
✅ The right thing to do:
• Log the failure with clear context
• Optionally route it to a DLQ for later analysis
• Don’t clog your system with futile retries
🛠 How to Detect the Type of Failure
Sometimes, just relying on status codes isn’t enough. Use a combination of:
• Error classification logic (e.g., custom error codes from APIs)
• Contextual analysis (e.g., was the system under load?)
• Heuristics + rules (e.g., 503 is often transient, but 422 is not)
You can also implement a tagging system like:
This helps systems decide: retry, discard, or escalate.
🧪 Bonus Tip: Test Your Failure Modes
Simulate both transient and permanent failures in staging. Validate that:
• Transient errors trigger retries correctly.
• Permanent ones go to DLQ or logs.
• Alerting and observability tools catch high failure rates.
💥 Don’t wait for production to teach you the difference.
DLQs: Not a Trash Bin, But a Signal
A Dead Letter Queue (DLQ) is often treated as a black hole where failed messages go to die — but that’s the wrong mindset. In reality, a DLQ is a diagnostic tool, a safety net, and a feedback loop all rolled into one. If you’re ignoring your DLQ, you’re missing out on valuable insights.
💡 What Is a DLQ, Really?
A DLQ in Amazon SQS is a secondary queue that receives messages that couldn’t be successfully processed after a defined number of retries (based on maxReceiveCount in your redrive policy).
It answers two critical questions:
• What’s broken in my system?
• Which messages need special handling?
🔍 Use DLQ as a Signal, Not Storage
Think of the DLQ as a canary in the coal mine:
• If DLQ size suddenly increases, something is wrong — a bad deploy, a broken API, or a data contract violation.
• Don’t let messages pile up silently — monitor DLQ metrics actively.
Set up alerts on:
• DLQ depth exceeding a threshold
• Spike in DLQ write rate
• Failure patterns (e.g., repeated 422 or 403s)
Example (CloudWatch Metric Alarm):
🧼 DLQ Hygiene: What to Do With Messages
Once messages are in a DLQ, you have options:
1. Analyze: Export the messages for offline inspection (via script or Lambda).
2. Fix & Replay: If the error was transient or fixable, push them back to the main queue.
3. Archive: For audit or traceability, store them in a database or S3 bucket.
4. Drop: If the error is known and non-recoverable (e.g., invalid user input), delete them after logging.
Remember: DLQs are not automatic retry queues. They’re a manual checkpoint.
🛠 Pro Tip: Include Metadata for Easier Debugging
When putting messages into the main queue, include enough metadata to debug later:
This makes DLQ triage much easier — no need to guess what caused the failure.
✅ Takeaway
DLQs aren’t a final resting place — they’re a signal to investigate, recover, and improve. Treat them with the same care you give to your production queues.
🧠 Conclusion: Retry Smarter, Not Harder
Retries are a powerful tool — but only when used with intention. Blindly retrying every failure is like hitting “refresh” on a broken page, hoping it magically fixes itself. Instead, building fault-tolerant queues with AWS SQS requires a deeper understanding of:
• When to retry (transient errors, 5xxs)
• When to fail fast (permanent errors, 4xxs)
• How to retry smartly (exponential backoff, jitter, retry limits)
• What to do when all else fails (Dead Letter Queues)
With proper design, you’ll build systems that bounce back from temporary issues, surface the right failures for investigation, and avoid overloading downstream services.
🚀 Whether you’re processing webhooks, orchestrating microservices, or moving messages across systems — resilient retry strategies separate robust applications from flaky ones.
Retry smarter. Monitor everything. Learn from failure.
🔗 Related Work
At NerdDevs, we focus on building resilient cloud architectures and intelligent systems that solve real-world engineering challenges. Our expertise includes optimizing AWS infrastructures and designing fault-tolerant services.
👉 Want to dive deeper into AWS optimizations?
Read our latest post: Optimizing AWS Load Balancing: Choosing the Right Stickiness Strategy